

Data science is concerned with the extraction of valuable information from structured, unstructured, or even both types of data. Because data is the competitive edge, one critical task of every data scientist is gathering valuable data for research.
Suppose you see information on the internet; the first idea that comes to mind is probably to copy and paste it, right? But what if the data is enormous to be copied and also in an invalid format that can't be saved as a document? That is when the concept of Web Scraping comes into play.

Web Scraping is an automatic method of extracting data from a website and importing it into a spreadsheet, database management system, or folder that can be saved on a local computer to be used in a variety of applications. It can therefore be referred to as one of the essential components of data science.
As previously stated, the type of data that can be scraped from the internet is either structured, unstructured, or both, and it may include texts, numbers, links, images, and any other vital information.
This article will explain the whole concept of Web Scraping and how it can be done with Python Programming Language. Without much hemming and hawing, let's get started😂.
Web scraping has grown considerably in recent years and has evolved into a widely known term in data science. One interesting thing about this method of data extraction is that it offers you access to this data anonymously regardless of your location.
Importance of Web Scraping
Although a technique that has both positive and negative consequences for users and experts, the following are some of the significant reasons why industries and professionals have adopted this technique of data retrieval.
- Automatic and Efficient: Manual data extraction is a costly and time-consuming operation that necessitates the participation of a significant number of people, resulting in an extensive budget.
Consider a project that requires a vast amount of data, such as texts, images, and so on. Most of the time, the data extraction process can take several days of downloading data to a folder or manually copying and pasting it.
By utilizing good tools, web scraping has reduced this time-consuming process to a simple and quick task.
- Cost Effective: Although dependent on the project's complexity or available resources, web scraping is guaranteed to be less expensive. Large funding is reduced so services and resource allocations will not tend to experience a drastic change in performance over time.
Furthermore, because these tools require little or no maintenance over time, overall budgeting is reduced.
Data Accuracy and Effective Data Management: When data is accurate, it is more reliable. Human errors caused by manual task performance can cause major issues in research and they must be avoided at all costs.
Data extracted via web scraping is the definitive choice of reliable data that can be used in effective research. Though errors are common and can be experienced, they can easily be corrected.
Simultaneously, data can be collected from websites and saved in computer-based software programs, where the information is secure and workers are not obligated to spend unnecessary extra time manually extracting data.
What Are The Application Of Web Scraping ?
Web scraping can be used in a variety of situations. The following are a few notable uses:
- Market survey or research
- Price Investigation
- News Surveillance
- Email Promotion
- Social media sentiment analysis
- House Rent Analysis etc.
False assumptions about web scraping
There are a few fables about data scraping that I'd like to dispel in this article.
Web scraping is not illegal, but some sites may impose restrictions or metrics that must be met before data can be extracted.
Not every website can be scraped! Some websites contain copyright-protected data, rendering data collected useless regardless of the time and energy invested in retrieval.
Scraped data are not only used for just business analytics. It has numerous applications in data science.
Web scraping can be executed using various tools such as import.io, octoparse, kimono labs, Mozenda, and programming languages such as Node.js, C, C++, PHP, and Python.
Python has emerged as the most effective tool for web scraping among the other tools and programming languages mentioned above due to its simple-to-learn syntax. Experts can manage various web scraping tasks with Python programming languages without any need for complex code.
There are three Python Frameworks (Libraries) that can be used for web scraping, however, in this article, I will only employ two: BeautifulSoup and Requests.
BeautifulSoup is commonly used to parse data from XML and HTML documents. Organizing this parsed content into more accessible trees, BeautifulSoup makes navigating and searching through large swathes of data much easier. It’s the go-to tool for many data analysts.
The first thing you need to do is to pip install the libraries in your python editor (PyCharm or Visual Studio) or Jupyter notebook. Though I will be working with an editor, you can access the Jupyter Notebook file for this exercise here
! pip install BeautifulSoup
! pip install requests
This automatically installs the two libraries and you are good to go.
The second step is choosing a site! Choose a site you would want to extract data from and copy the web address. In this exercise, I would extract data from Nigeria Property. Nigeria Property is a website where anyone can view and rent vacant apartments within Lagos (Main Land and Island).
Once you have your site URL, you can kick-start the process.
#import the libraries
from bs4 import BeautifulSoup
import requests
from CSV import writer # writes the data to be extracted into CSV files
Now you are done importing the required libraries, initialize a variable for the website URL
url = "https://nigeriapropertycentre.com/for-rent/flats-apartments/lagos/showtype?gclid=Cj0KCQjworiXBhDJARIsAMuzAuzsjliytrKCQUWynjzo-Rv9rSdi9mHbWNTGynIs54NVbvxS2JODptwaAhn-EALw_wcB"
page = requests.get(url) #grabs data from it source to your editor or jupyter notebook.
Inspect the website already to learn more about HTML documents. You can inspect a website by simply right-clicking and selecting the inspect feature which displays the site's Html documents. To make the task easier, highlight and inspect whatever information on the website that you would love to work with.
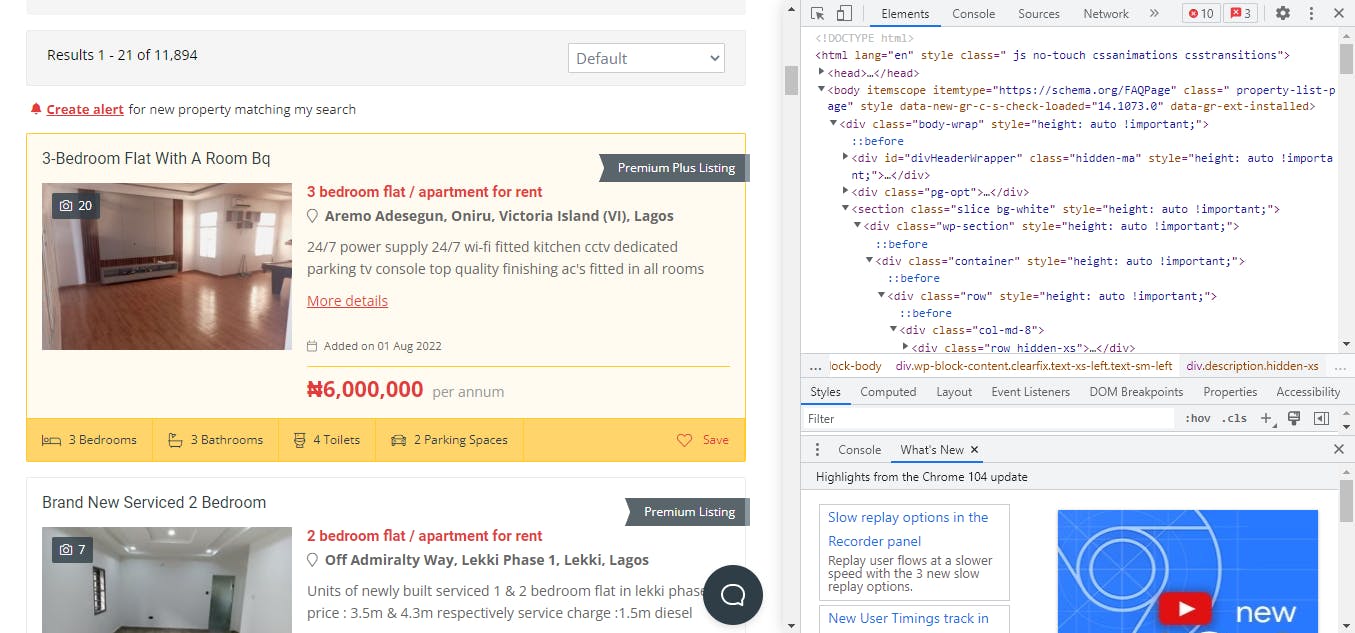
On this website, I only need three pieces of information: the title, the location, and the price_per_period. To make things easier for myself, I can highlight a specific section to inspect. It is best to begin with the first section and use a loop to get all of the information on the remaining sections.
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('div', class_= "wp-block property list") #this is the mother div and class that has the section information
N.B: The mother div and class in this context highlight every piece of information in a given section just as in the image below.
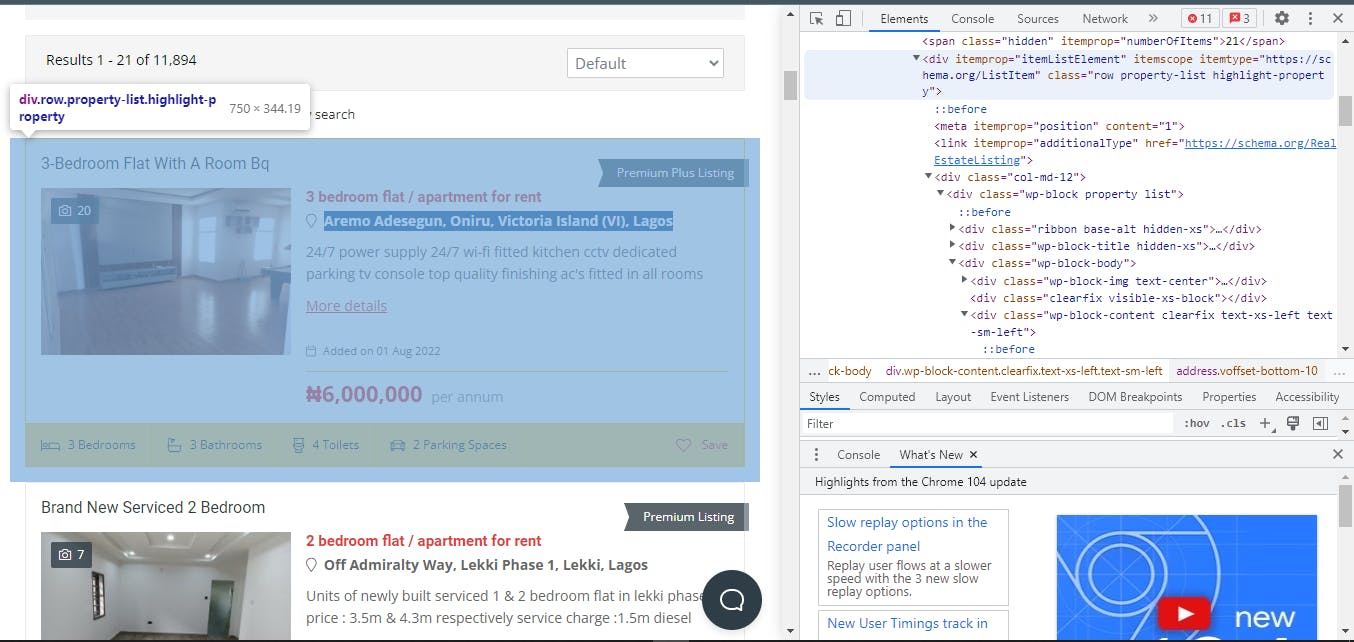
Once you get to this point, use the same method (corresponding HTML tag ) to get information for the title, location, and price!
with open('LagosApartment.csv', 'w', encoding='utf8', newline='') as f:
thewriter = writer(f)
header = ['Description ', 'Location', 'Price_and_Duration']
thewriter.writerow(header)
# This function writes the extracted data into a csv format
for list in lists:
title = list.find('h4', class_="content-title").text.replace('\n', '')
address = list.find('address', class_="voffset-bottom-10").text.replace('\n', '')
price = list.find('span', class_="pull-sm-left").text.replace('\n', '')
#The for loop is used to get similar information from all the sections
info = [title, address, price]
thewriter.writerow(info) #writes info variables into corresponding header.
We are done and probably you are excited! As I previously stated, the For Loop simplifies the entire task! Note that these sites contain various apartments in various locations and at various prices_per_period; the for loop collects this variety of information all at once, making the entire process easier.
At this point, you should have a CSV file titled Lagos Apartment in your editor.
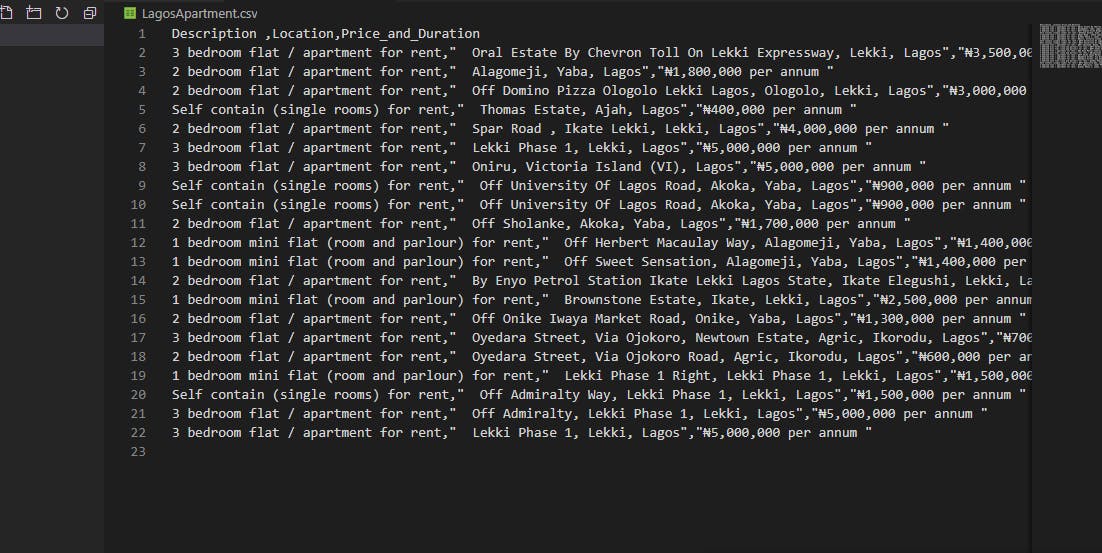 .
.
Below is the entire code
from bs4 import BeautifulSoup
import requests
from csv import writer
url = "https://nigeriapropertycentre.com/for-rent/flats-apartments/lagos/showtype?gclid=Cj0KCQjworiXBhDJARIsAMuzAuzsjliytrKCQUWynjzo-Rv9rSdi9mHbWNTGynIs54NVbvxS2JODptwaAhn-EALw_wcB"
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all('div', class_= "wp-block property list")
with open('LagosApartment.csv', 'w', encoding='utf8', newline='') as f:
thewriter = writer(f)
header = ['Description ', 'Location', 'Price_and_Duration']
thewriter.writerow(header)
for list in lists:
title = list.find('h4', class_="content-title").text.replace('\n', '')
address = list.find('address', class_="voffset-bottom-10").text.replace('\n', '')
price = list.find('span', class_="pull-sm-left").text.replace('\n', '')
info = [title, address, price]
thewriter.writerow(info)
CONCLUSION
Hopefully, you enjoyed reading about web scraping, and if you followed the exercise, you would have become acquainted with the entire web scraping process using Python. Great! Now that you have your data, proceed to perform any necessary operations on it.